Dependency Injection - The good, the bad and the ugly
The Good
I've worked on quite a few projects employing Spring, so it will be my framework of reference throughout the rest of the post, but the principles and morals apply just the same.
The official Spring IoC container documentation depict things like so: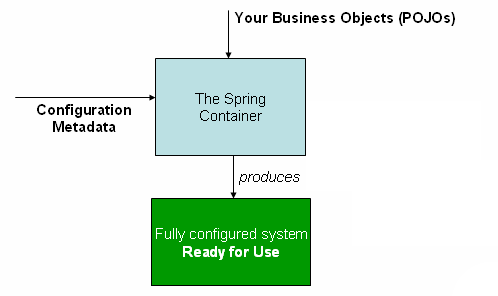
The "Configuration Metadata" part in this chat is usually provided by either a programmatic or an XML based API. We'll concentrate on the XML based API which appeals to many as it creates a soft of separation between your code and your wiring logic, which is confined to a set of XML files thus making the code oblivious to the DI magic taking place behind the scenes. A true bliss.
We can look at it as 2 conceptual piles:
- Business logic - Code files
- Wiring logic - A Spring XML file that wires our business classes together
The Bad
There's just this little thing called unit testing, where you want to test your classes, features and whatnot in a relatively isolated setup. "No problem", one might think, "unit testing is one of the glorious benefits DI provides, dependencies are injected, so you can mock pretty much anything you like - happy unit testing". The thing is, one can't really use his Spring XML file in his tests because it loads the all the"real" objects, not his mocks. In order to surmount this hurdle, one resorts to doing the wiring manually, creating instances by hand, and wiring them together, by hand. So now we have 3 conceptual piles:
- Business logic - Code files
- Wiring logic - A Spring XML file that wires our business classes together
- Tests - A mix of test logic and wiring logic, since tests construct their own object graph (and plug mocks where needed)
Although 3 piles is ~50% more than 2 piles, things work great. For a while.
It's on a rainy Tuesday that you are contacted about a bug, "strange" you think to yourself, "I thought I had it covered in a test". You dig deeper and discover that your unit test creates a slightly different object graph than your Spring XML files, and the bug at hand just happens to be in that one class you did not load in your test, because, well, it's a test.
With time, an application's object graph is bound to become deeper and deeper, turning manual object graph construction, in code, object by object, into a rather tedious task. This greatly increases the chances of the object graph constructed in tests being different from the one created in production, by the Spring XML files. We're not talking about the differences introduced by mocks, crafted to remove a particular dependency, these are (hopefully) accounted for. We're talking about the unaccounted stuff, that null you passed to some constructor because you KNOW it's not being used in a particular test, or this other object you did not "new" because you KNOW it's not required for this test to pass (guess what, in production that object does get new'd and its ctor throws an exception).
The bottom line is, even if we don't count mocks in, tests' and production's object graphs may considerably differ, because each does its wiring differently. While tests use direct object instantiation in code, in production, the application employs Spring and loads its object graph using a Spring XML file.
The (sometimes) Ugly
If only we could use the same wiring mechanism for the tests and the production code... Well, turns out we can, if our Spring XML files are built in a modular way. The thing is, we can use the Spring XML files from within our tests, and have them construct the object graph, similarly to the way they do in production. The only but here, is that we still need a way to mock certain things.
By placing the objects you'd like to mock in dedicated Spring XML files, apart from the non objects you're not going to mock, you can tweak your test to load the test-specific Spring XML files instead of the original ones, and thus effectively replace the original objects with the mocked ones. What makes is all play nicely is the the fact wiring takes place according to a bean's name, so as long as you provide a bean named the same way, the wiring contract is fulfilled and the object graph is happy.
In a way, one can look at it as Spring XML file modularity, instead of making it monolithic, we break it up into multiple XML files, each responsible for a different aspect of the application. This way, we always construct the object graph with Spring, it's just that in tests a different set of files is loaded. If we design things carefully, we can surgically replace objects with mocks by loading a different Spring XML file, without having to fall back to manual object graph construction. By reusing existing Spring XML files (note the part circled green in the figure below) and replacing only a small subset of them in our tests, we keep the differences between our test's and production's object graph to a minimum.

At the end of the day the main point here is modularity, and the fact we're better off applying modularity concerns to our Spring XML files, much the same way we do to our code. It is modularity that allows us to replace one component with another without breaking the whole system. In the case of DI and XML based configuration, it is modularity that allows us to use the same wiring mechanism and keep differences to a minimum between tests and production setups, without taking away our ability to plug in mocks where we see fit.

Comments
Post a Comment